World Modelling in Embodied AI
Developing structured world models to enable more robust, adaptive, and data-efficient embodied intelligence, with autonomous driving as a core testbed
We develop structured world models to enable more robust, adaptive, and data-efficient embodied intelligence, with autonomous driving as a core testbed. Our research spans four directions: (i) enhancing rule understanding via generative world models, (ii) unifying multimodal understanding and generation, (iii) bridging simulation and reality for embodied robots, and (iv) learning high-level concepts for data-efficient driving intelligence. Together, these efforts aim to build agents that are safer, more adaptive, and capable of robust generalization in complex real-world environments.
Part 1: Enhancing Rule Understanding in Autonomous Driving Systems Using Generative World Models
Our Objective:
The core of an autonomous driving system lies in its deep understanding of the surrounding environment and traffic rules. However, current autonomous driving technology still faces challenges when dealing with complex or rare high-level rules. For instance, "How should the system decide when a police officer's hand gesture conflicts with traffic signal indications?" Such situations highlight the current system's shortcomings. Therefore, integrating these complex rules effectively into autonomous driving models becomes a critical issue for improving system reliability. The cause of this problem is the "long tail effect" of real-world data: rare but crucial hazardous scenarios are extremely sparse in datasets. Relying on manual data collection for such scenarios is not only costly but also entails significant safety risks. To address this challenge, our research utilizes Generative AI to construct a data feedback loop framework. This framework uses a Generative World Model to create large-scale simulation scenes that include complex high-level rules and complete 3D ground truth. These high-quality synthetic data are then used to train the main driving model, compensating for its shortcomings in rule understanding, and ultimately improving its decision-making ability in real-world environments.

Figure 1: Enhancing Rule Understanding Using Generative World Models.
Our Achievements So Far:
- 1. Static World Construction: Achieved fine-grained control in generating static 3D driving scenes. (Yang* et al., 2023)
2. Dynamic World Synthesis: Expanded the model to include temporal sequences, resulting in the continuous generation of 4D video, demonstrating the model's performance in dynamic environments. (Ma* et al., 2024)
3. Model Self-Correction: Built the data feedback loop framework, enabling the system to learn from the generated data and perform self-correction and optimization. (Ma* et al., 2024)
4. Multimodal Joint Generation: By unifying multimodal features through a shared Bird's Eye View (BEV) space, we achieve consistent joint generation of multimodal sensor data, enhancing the multimodal perception capability of autonomous driving systems. (Tang et al., 2025)
5. Trajectory Risk Prediction Enhancement: By using synthetic trajectory data, we enhanced the Visual Language Model (VLM) in predicting the risks associated with planned trajectories, thereby improving the safety of the planned trajectories. This advancement helps foresee potential risks in real driving scenarios, optimizing the safety of autonomous driving decisions. (Hou* et al., 2025)
Future Outlook
We will continue to optimize the self-correcting feedback loop framework, enhance the realism of the simulator, and improve high-level closed-loop capabilities. Our goal is to reduce data collection and training costs, further enhancing the robustness and generalization of autonomous driving models, ultimately driving autonomous driving technology toward a smarter and safer future.
Part 2: Unifying Muti-modal Understanding and Generation
Our Objective:
We believe that understanding and generation are two sides of the same coin in perceiving the world: deeper understanding enables more precise generation, while the ability to generate in turn reinforces the model’s grasp of the underlying patterns of the world. Toward this vision, we focus on (i) constructing more effective unified MLLM architectures, (ii) developing unified discrete/continuous multimodal representations, (iii) designing more effective visual tokenization methods, and (iv) exploring how generative capabilities can be leveraged to genuinely enhance understanding.
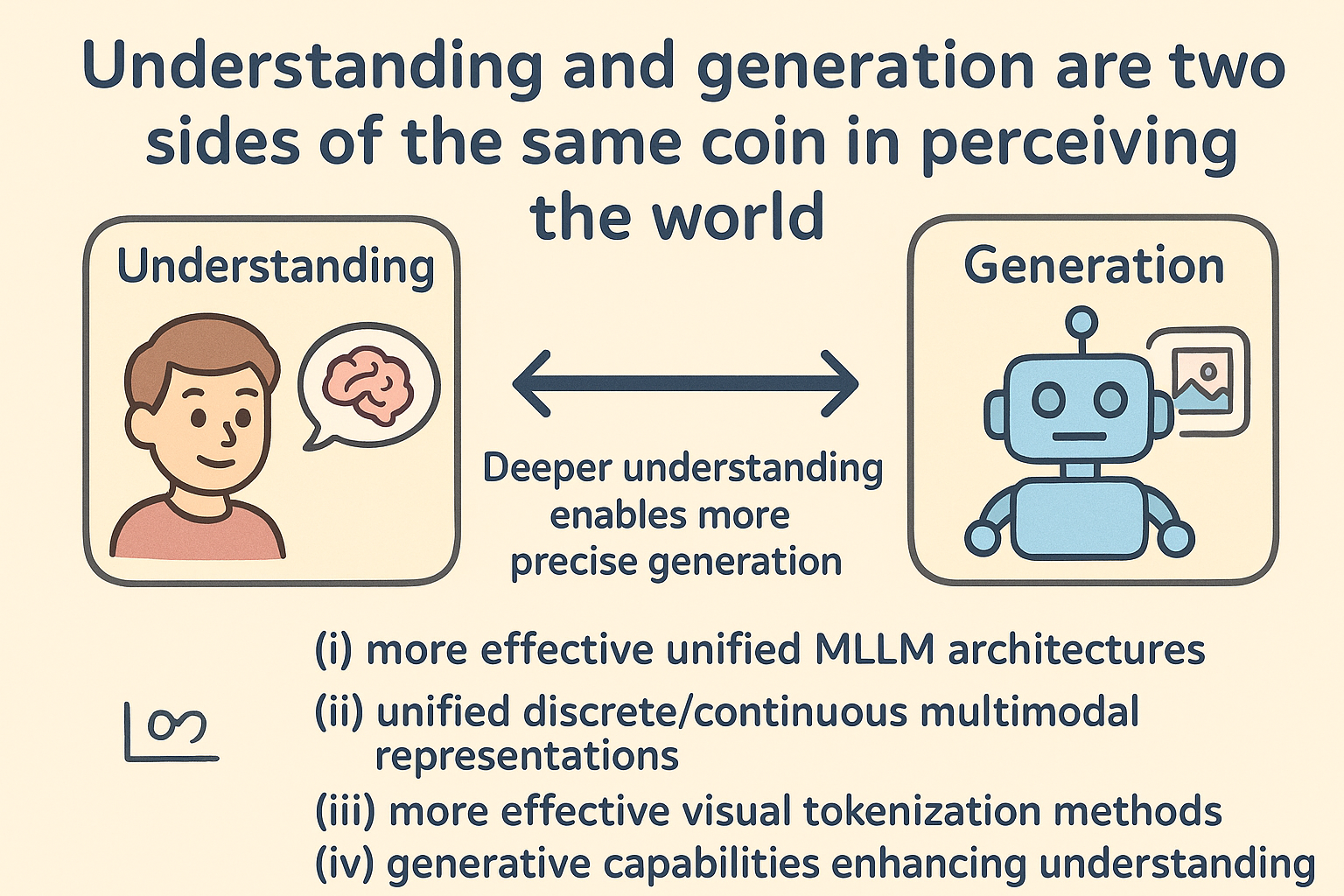
Figure 2: Understanding and generation are two sides of the same coin.
Our Achievements So Far:
- 1. Unified Visual Tokenizer: We proposed DualToken, a unified visual tokenizer for both understanding and generation. To disentangle the conflict between understanding and generation, we introduced separate codebooks for semantic and pixel-level objectives in visual tokenzier. DualToken achieves state-of-the-art performance in both reconstruction and semantic tasks while demonstrating remarkable effectiveness in downstream MLLM understanding and generation tasks. (Song et al., 2025)
2. Can visual generation supervision enhance VLMs' understanding? We found that autoregressively reconstructing visual semantics can leads to stronger visual-language comprehension. (Wang* et al., 2025)
Future Outlook
First, we aim to design more efficient and scalable tokenization mechanisms that can flexibly adapt to diverse modalities beyond vision and language, such as audio and video. Second, we intend to investigate how generative objectives can be more tightly integrated with understanding tasks, enabling mutual reinforcement between generation and understanding. Third, we envision applying our framework to real-world applications, such as embodied AI, to validate its broader impact.
Part 3: From Simulation to Reality: Toward Autonomous Embodied Robot
Our Objective:
Human can quickly adapt to new environments and tasks by leveraging prior knowledge, physical intuition, and high-level reasoning. In contrast, robot often rely on massive-scale data collection and environment-specific training, yet still struggle to generalize across diverse scenarios and perform reliably in the real world. Our research focuses on bridging this gap by developing agents capable of transferring skills from simulation to the real world (Sim2Real), while building structured world models that enable generalizable reasoning, robust planning, and adaptive decision-making. We aim to move beyond brute-force imitation learning and toward data-efficient, autonomous intelligence.
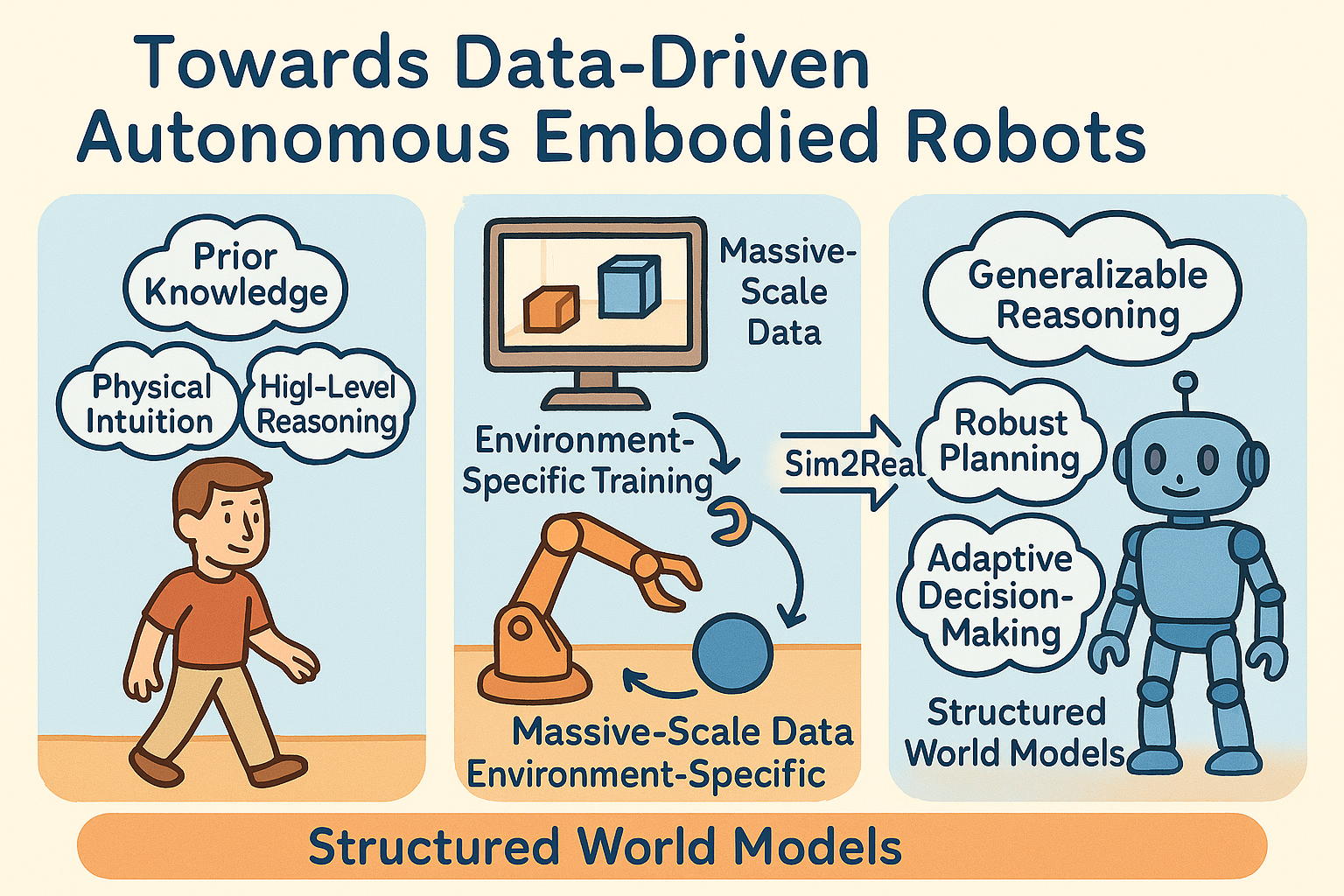
Figure 3: Towards Data-Driven Autonomous Embodied Robot.
Our Achievements So Far:
- 1. Generative Simulation Module: We propose a generative simulation module capable of diverse training scenes. This enables continuous policy generation and refinement within a closed-loop pipeline, where simulated experiences directly guide policy learning, and improved policies, in turn, trigger automatic generation of more challenging environments.
2. Socially-Enhanced Navigation Policy: To handle complex multi-agent environments, we introduce a socially-enhanced navigation policy that incorporates social attributes and interaction modeling into policy learning. By embedding social compliance, comfort metrics, and group dynamics into the reward structure, our agents achieve significantly better performance in crowded, dynamic, and socially-constrained navigation tasks.
Future Outlook
We plan to extend our framework to more diverse tasks and heterogeneous robotic platforms, enabling agents to autonomously collect data, learn concepts, and adapt policies online with minimal human supervision. Our long-term goal is to establish a unified paradigm for autonomous embodied intelligence, where agents not only learn efficiently from limited data but also generalize robustly to unseen environments, novel tasks, and real-world uncertainties.
Part 4: From Data to Concepts: Toward Efficient Driving Intelligence
Our Objective:
Human drivers typically require only limited formal training—covering traffic rules, basic operations, simulated road practice, and driving norms—before gradually adapting to increasingly complex and unfamiliar situations with experience. In contrast, autonomous driving systems have consumed millions or even billions of data samples, yet achieving fully reliable performance still remains a challenge. Our research explores whether autonomous agents can move beyond brute-force data accumulation by developing higher-level conceptual understanding from their training, somewhat akin to the human ability to generalize through intuition. We believe such an approach could lead to more data-efficient learning and enable agents to handle rare and long-tail scenarios more effectively. (missing reference)
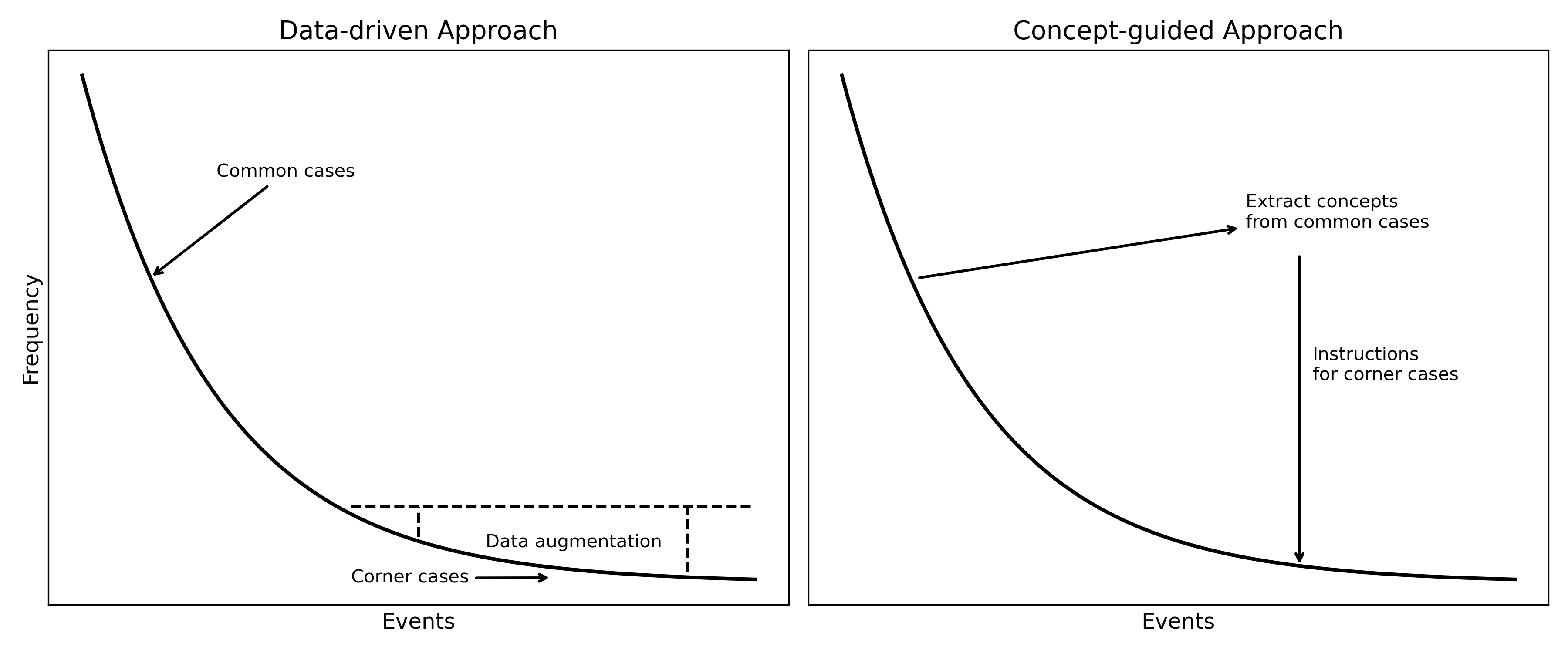
Figure 4: Comparison between data-driven and concept-guided approaches.
Our Achievements So Far:
- 1. Concept-Learning Module: We are developing a concept-learning module that complements existing end-to-end driving architectures.(missing reference) This module aims to build a structured understanding of driving scenarios in parallel with traditional perception and control pipelines.
Future Outlook
We plan to extend this framework using more diverse datasets to improve the generalization of the concept model, with the ultimate goal of enhancing performance in unseen and complex situations while advancing the broader pursuit of data-efficient learning in autonomous driving.
References
2025
-
 OmniGen: Unified Multimodal Sensor Generation for Autonomous DrivingIn Proceedings of the 33rd ACM International Conference on Multimedia, 2025
OmniGen: Unified Multimodal Sensor Generation for Autonomous DrivingIn Proceedings of the 33rd ACM International Conference on Multimedia, 2025 -
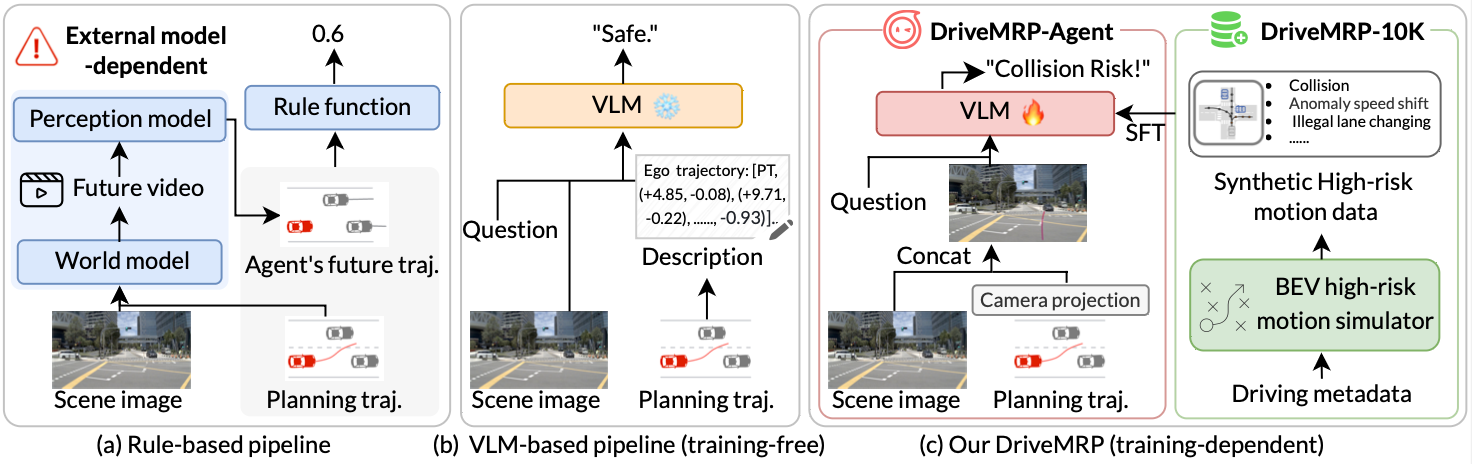 DriveMRP: Enhancing Vision-Language Models with Synthetic Motion Data for Motion Risk PredictionarXiv preprint arXiv:2507.02948, 2025
DriveMRP: Enhancing Vision-Language Models with Synthetic Motion Data for Motion Risk PredictionarXiv preprint arXiv:2507.02948, 2025 -
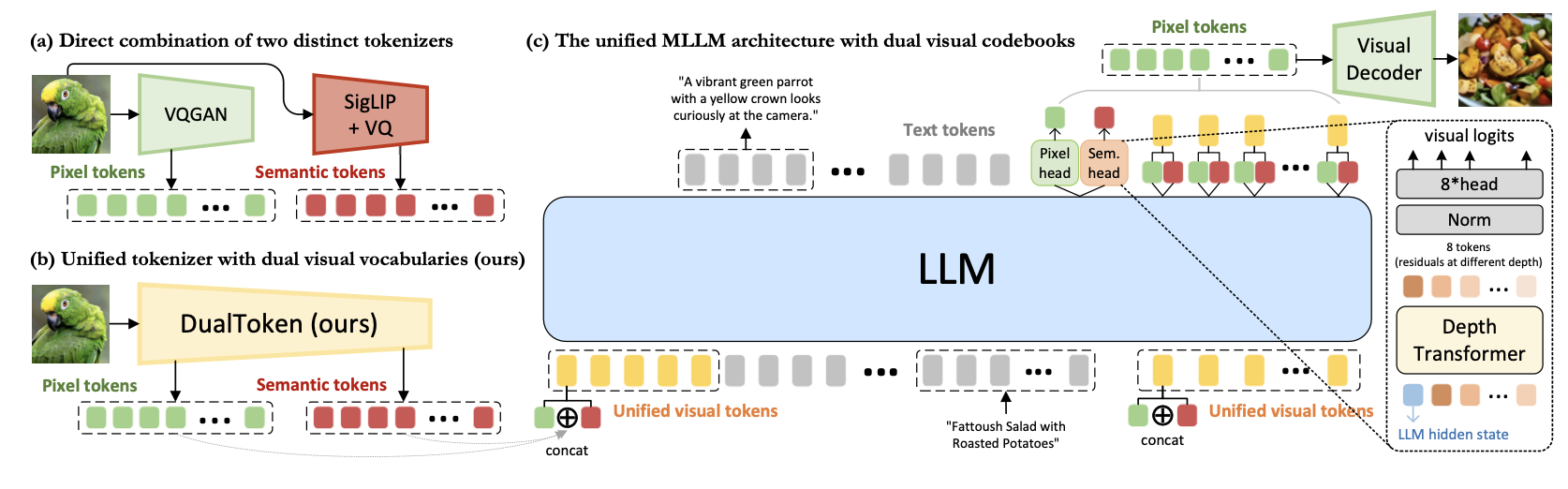 Dualtoken: Towards unifying visual understanding and generation with dual visual vocabulariesarXiv preprint arXiv:2503.14324, 2025
Dualtoken: Towards unifying visual understanding and generation with dual visual vocabulariesarXiv preprint arXiv:2503.14324, 2025 -
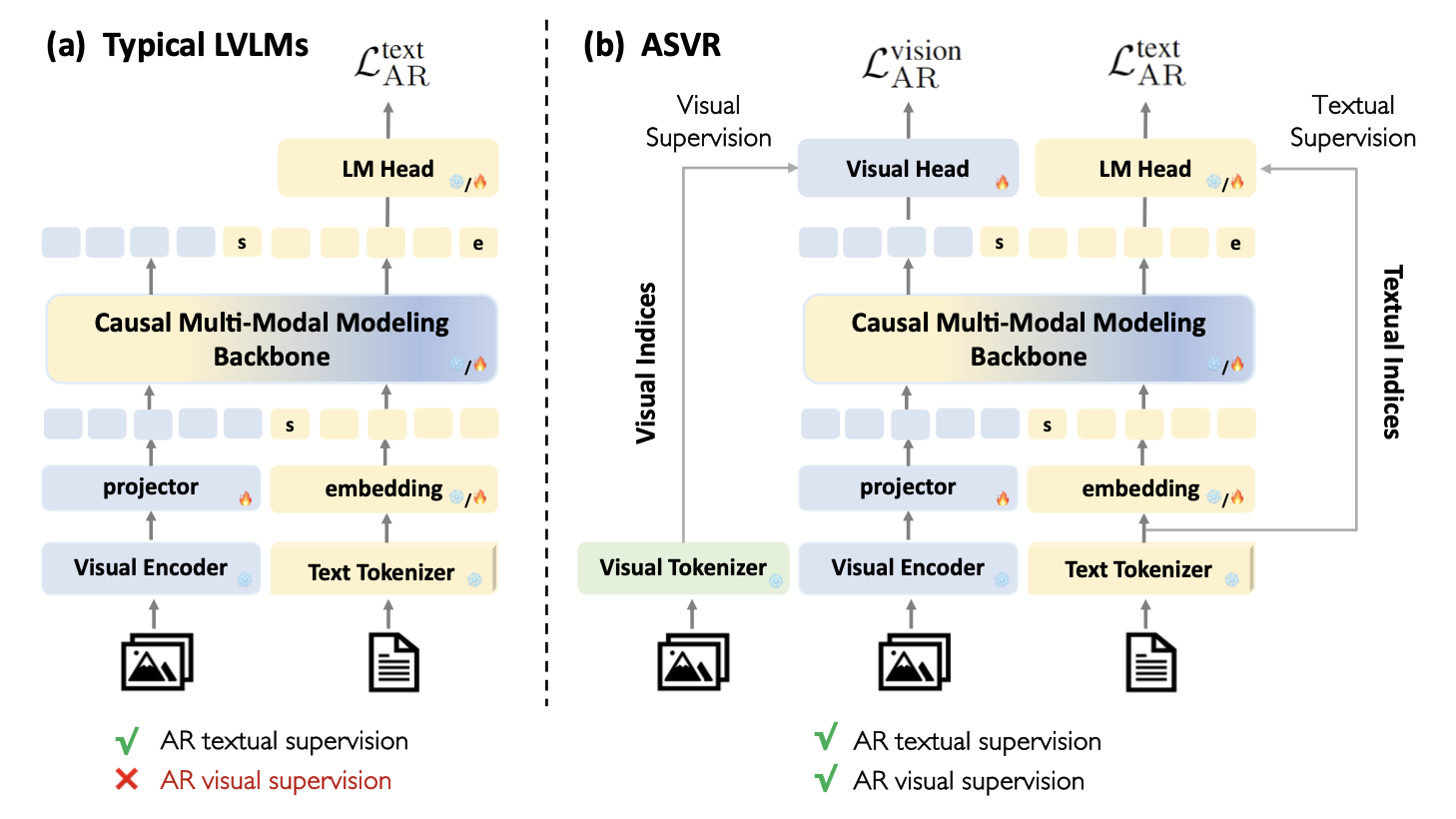 Autoregressive semantic visual reconstruction helps vlms understand betterarXiv preprint arXiv:2506.09040, 2025
Autoregressive semantic visual reconstruction helps vlms understand betterarXiv preprint arXiv:2506.09040, 2025




2024
-
 Unleashing generalization of end-to-end autonomous driving with controllable long video generationarXiv preprint arXiv:2406.01349, 2024
Unleashing generalization of end-to-end autonomous driving with controllable long video generationarXiv preprint arXiv:2406.01349, 2024

2023
-
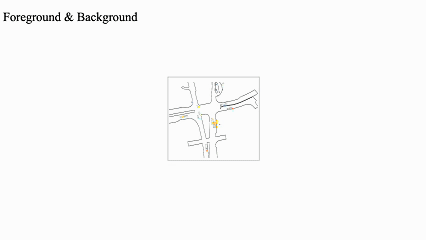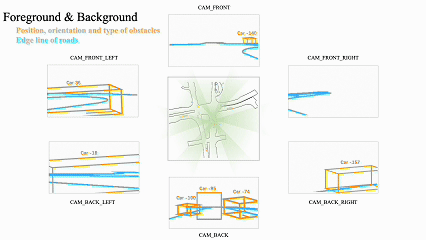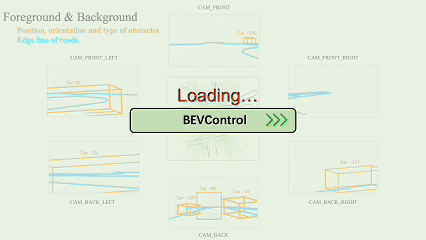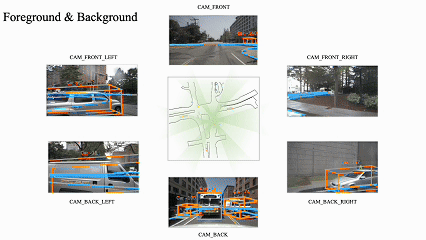 Bevcontrol: Accurately controlling street-view elements with multi-perspective consistency via bev sketch layoutarXiv preprint arXiv:2308.01661, 2023
Bevcontrol: Accurately controlling street-view elements with multi-perspective consistency via bev sketch layoutarXiv preprint arXiv:2308.01661, 2023
