Autonomous Intelligence Modeling
Enhancing deep reasoning and systematic generalization in large models through an Autonomous Intelligence Framework that integrates symbolic rules and data.
Our core research agenda is to build an Autonomous Intelligence Modeling (AIM) framework—an intelligent, rule-grounded, data-efficient, and adaptive modeling pipeline designed to enhance the core capabilities of large language models (LLMs) and vision-language models (VLMs). To this end, we focus on three interrelated directions: (i) A training-and-inference framework that unifies induction and deduction. We aim to deeply integrate data-driven inductive capabilities with logic-driven deductive reasoning across the entire LLM training and inference lifecycle, reducing dependence on massive datasets and establishing a more efficient and interpretable paradigm for learning and reasoning. (ii) Rule-based inference augmentation for LLMs and VLMs. To address fundamental limitations in handling abstract compositional structures and complex spatial relations, we investigate a rule-driven paradigm that augments model inference with explicit rules. (iii) VLM cognitive reasoning over complex symbolic systems. Using oracle bone script and other ancient writing systems as representative cases, we explore VLMs' ability to understand, analyze, and reason about highly regularized visual symbol systems. This interdisciplinary application serves as a rigorous test of the effectiveness of rule-augmented methods for complex visual reasoning and symbolic generalization. Together, these lines of work form a more intelligent and robust modeling-and-reasoning system that fundamentally strengthens the deep reasoning and systematic generalization abilities of current LLMs and VLMs.
Part 1: An Induction-Deduction Dual-Driven Inference Paradigm
Our Objective:
Current large models are primarily built on a data-driven inductive learning paradigm. While this paradigm excels at extracting statistical regularities and high-dimensional representations from massive datasets, it also introduces inherent theoretical bottlenecks in logical rigor, data efficiency, and interpretability. On the one hand, overreliance on induction makes the reasoning process akin to "intuitive" pattern matching, lacking a deep understanding of causal relations and logical axioms; as a result, models can be brittle and inconsistent when facing entirely novel or logically complex tasks. On the other hand, this paradigm demands vast amounts of training data, limiting applicability in data-sparse domains, and its "black-box" nature makes reasoning paths difficult to trace and verify, constraining deployment in sensitive settings.
To address these challenges, this research direction aims to construct a unified reasoning framework that integrates induction and deduction, fundamentally reshaping the model's learning and reasoning mechanisms. We plan to explore a Neuro-Symbolic Co-architecture that organically combines the powerful representation learning of neural networks with the explicit logical reasoning of symbolic systems. During training, we will embed symbolic domain knowledge (e.g., axioms, rule bases) and logical constraints into the learning objective as differentiable regularizers or structured priors, guiding neural networks to learn more logically consistent internal representations and thereby substantially improving data efficiency and convergence speed. During inference, we will build an iterative reasoning loop—"Generate-and-Verify" or "Hypothesize-and-Refine." The data-driven inductive module rapidly proposes high-probability hypotheses or preliminary conclusions from context, while the knowledge-driven deductive module applies formal rules to check these hypotheses, perform causal inference, revise or reject them, and produce a rigorous, auditable chain of reasoning.
Our ultimate goal is to establish a new, efficient training-and-inference paradigm that combines data-driven insight with logical rigor. Through this framework, we aim to significantly enhance models’ systematic generalization in zero/few-shot settings, the interpretability of their reasoning processes, and their robustness against adversarial perturbations, thereby advancing subsequent research on “rule augmentation” and “complex symbol understanding.”
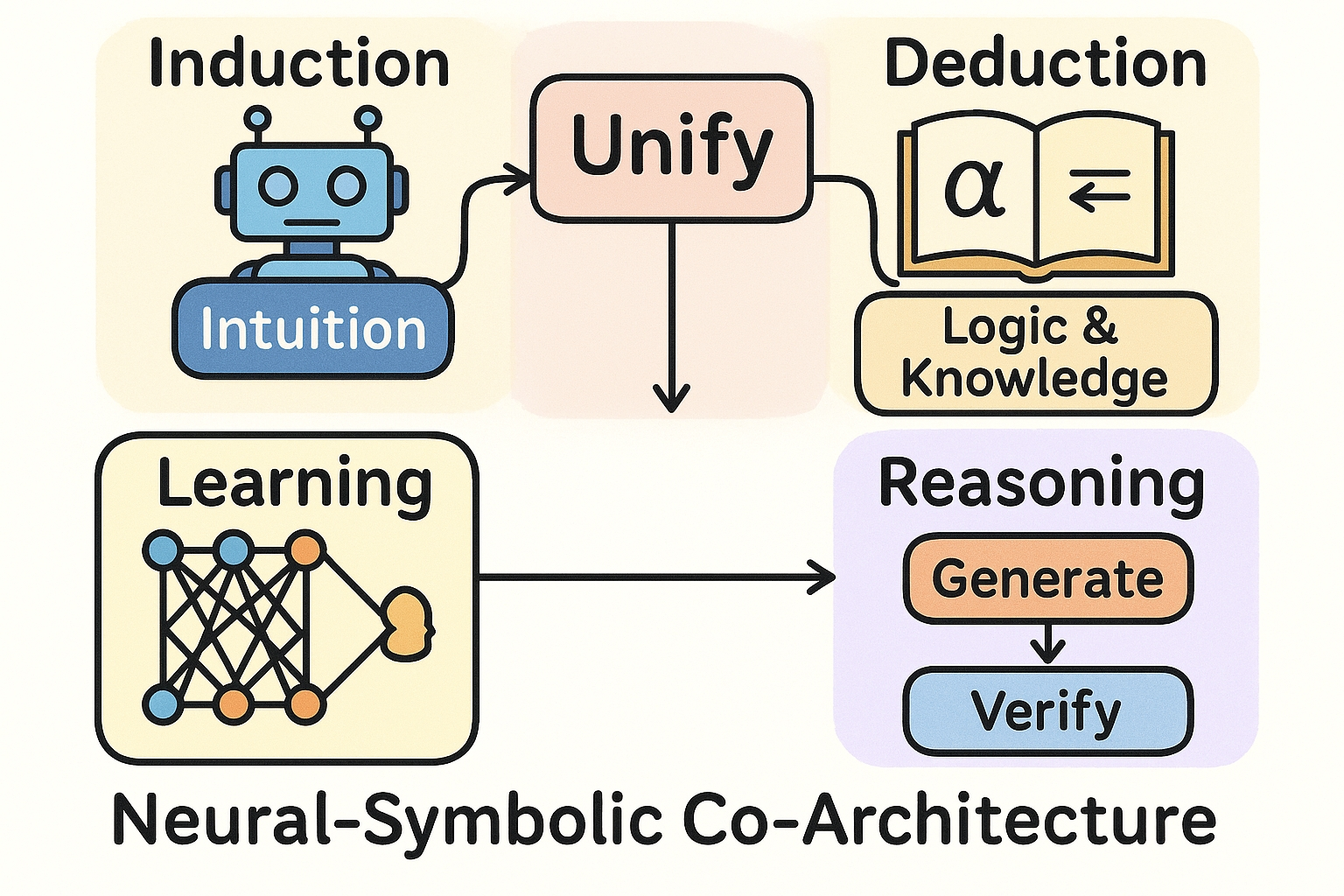
Figure 1: Integrating neural intuition with symbolic logic for robust and verifiable AI .
Our Achievements So Far:
- 1. Induction–Deduction Training Paradigm
We propose a deductively guided inductive training paradigm designed to fundamentally improve the efficiency and quality of model training. Its core mechanism converts symbolic deductive logic (e.g., domain rules, logical axioms) into differentiable constraints or regularization terms and integrates them into the loss function of inductive models (neural networks). In this way, deductive logic can guide and calibrate the direction of gradient descent in real time, effectively constraining the model’s hypothesis space. By enhancing the informativeness of the learning signal, this paradigm aims to achieve faster convergence, greater data efficiency, and ensure that the model begins learning logically consistent internal representations from the outset of training.
Future Outlook
We will further advance the deductively guided inductive training paradigm by exploring mechanisms to automatically induce and refine symbolic rules from data, and by extending the paradigm from offline training to hybrid reasoning architectures that regulate inference in real time. Our goal is to build a self-evolving neuro-symbolic system that further reduces reliance on large-scale labeled data and ultimately advances AI toward a higher form capable of verifiable, interpretable, and self-consistent reasoning.
Part 2: Rule-Driven Enhancement of LLM and VLM Reasoning
Our Objective:
Recent advances in large language models (LLMs) and vision-language models (VLMs) have yielded significant progress in multimodal reasoning, yet these systems remain fundamentally limited when confronted with rule-intensive and highly complex scenarios. LLMs often experience performance degradation when directly processing abstract semantic representations, largely due to their lack of robust symbolic alignment at the semantic level. Meanwhile, VLMs perform particularly poorly in spatial deformation reasoning, especially in multi-step, high-dimensional three-dimensional tasks, where their capabilities fall far short of human-level reasoning. To address these challenges, this project proposes a rule-driven paradigm for reasoning enhancement: in language reasoning, by integrating structured representations with natural language to improve logical consistency; and in visual reasoning, by establishing an infinitely scalable ladder-style evaluation framework to drive the evolution of models’ dynamic spatial reasoning abilities. Our objective is to explore how rule-driven mechanisms can function as a scaffolding framework for reasoning, thereby enhancing the robustness and generalization of multimodal models in complex and hierarchical tasks.
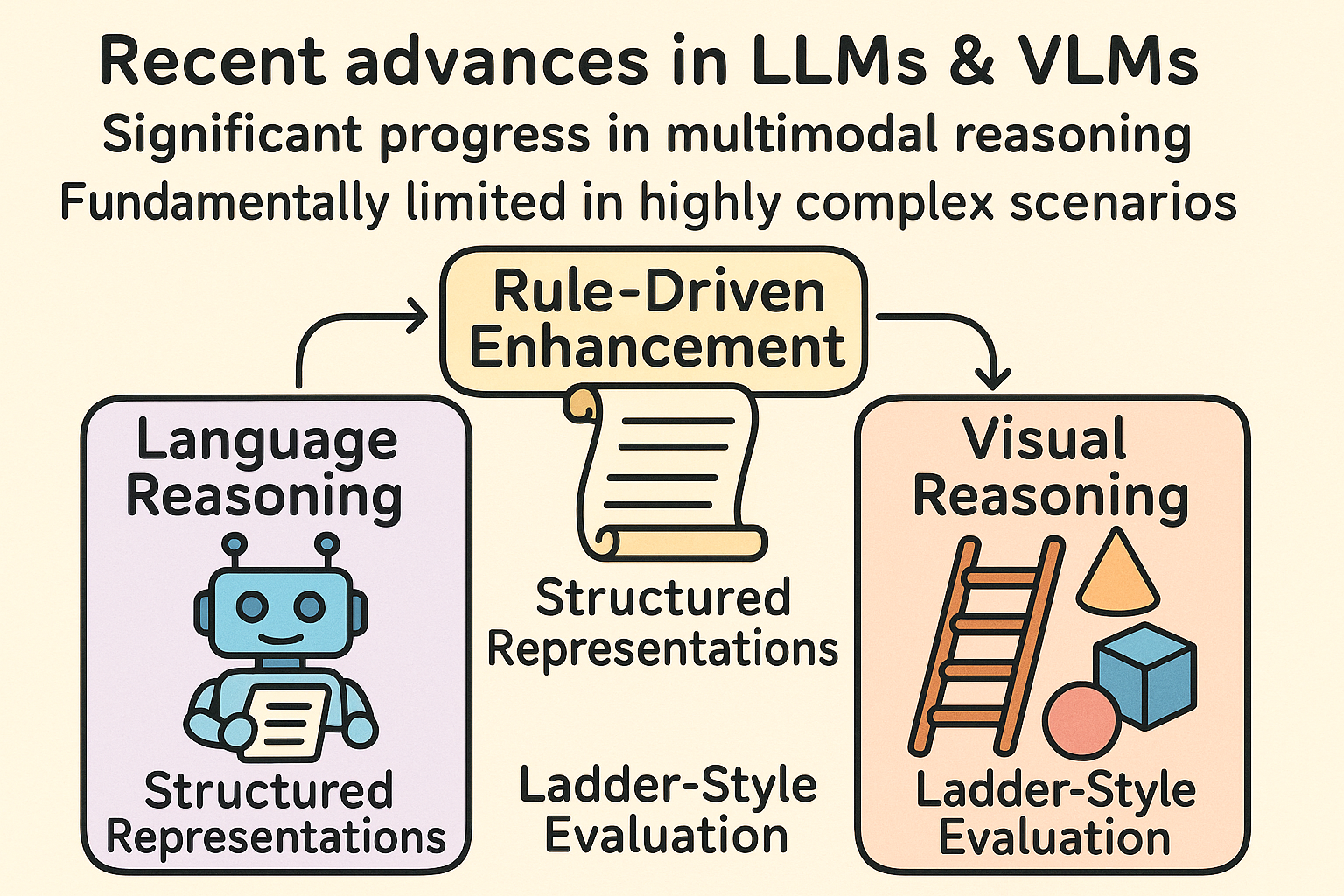
Figure 2: Enhancing large models with rule-driven language and visual reasoning.
Our Achievements So Far:
- 1. Structured Representation-Driven Enhancement
We proposed the SR-LLM framework, which transforms abstract semantic representations into naturalized inputs under rule-based guidance and integrates supervised fine-tuning with hybrid datasets, leading to substantial improvements across multiple language reasoning tasks. (Zhang et al., 2025)
2. Spatial Deformation Reasoning Benchmark
We developed Inf-Bench, a rule-based and infinitely scalable benchmark for spatial deformation reasoning, which systematically exposes the fundamental limitations of existing models in multi-step three-dimensional reasoning. (Zhang et al., 2025)
Future Outlook
We will continue to refine the rule-driven reasoning framework by deepening the integration of structured representations with language models and enhancing the stability and scalability of vision models in high-dimensional spatial reasoning. Our goal is to reduce the training and evaluation costs of complex reasoning tasks, thereby strengthening the robustness and generalization of multimodal models and ultimately advancing AI systems toward more systematic and reliable reasoning capabilities.
Part 3: VLM-based Cognitive Reasoning for Complex Symbolic Systems
Our Objective:
In recent years, vision-language models (VLMs) have achieved remarkable progress in general multimodal reasoning tasks, demonstrating strong capabilities in cross-modal understanding and generation. However, when confronted with complex symbolic systems, VLMs still face significant challenges and struggle to fully exploit their potential. Taking oracle bone inscriptions as an example, this symbolic system is essentially a pictographic representation of the real world, embedding intricate spatial structures and semantic logic. Yet, existing VLMs encounter great difficulty in transferring their acquired understanding from general-domain tasks to the oracle bone system, which prevents effective analysis and reasoning.
To address this issue, we propose VLM-based cognitive reasoning for complex symbolic systems, aiming to guide VLMs in conducting cognitive analysis and logical reasoning within the oracle bone system, thereby deepening their understanding of complex symbols. Unlike general scenarios, this research treats symbolic systems as highly abstract and symbolic multimodal inputs, and explores how to construct mappings between symbols and semantics under limited supervision and knowledge transfer conditions.
Our goal is not only to enhance the spatial reasoning ability of VLMs in oracle bone recognition and interpretation, but also to foster the model’s adaptability to a broader range of complex symbolic systems, such as other ancient scripts, mathematical formulae, and scientific notations. Ultimately, we expect this line of research to further strengthen the spatial understanding and abstract reasoning abilities of VLMs in general domains, pushing forward their performance in more challenging multimodal cognitive tasks.
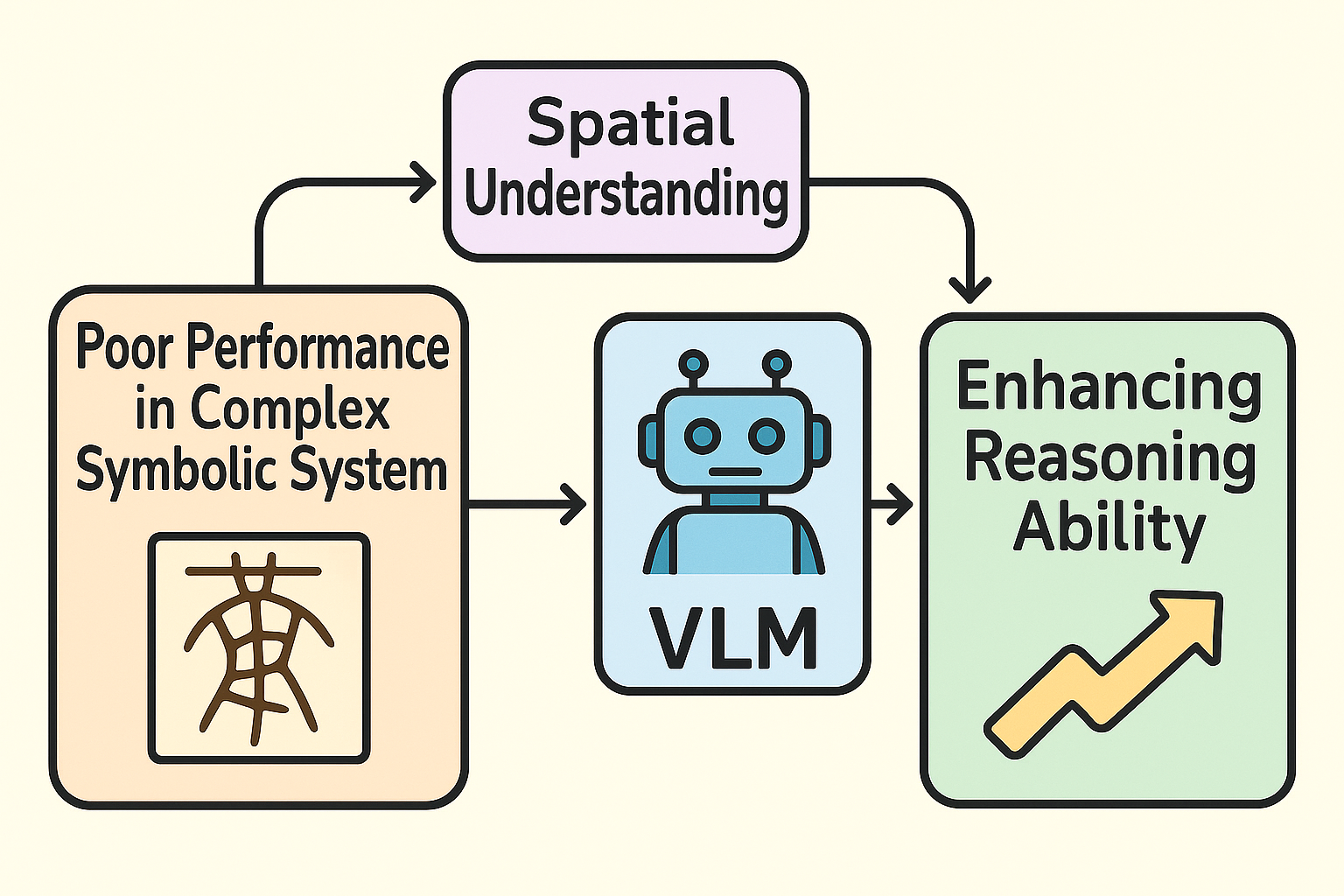
Figure 3: Enhancing VLM reasoning on complex symbols via spatial understanding.
Our Achievements So Far:
- 1. Construction of a complex symbolic reasoning dataset centered on Oracle Bone Script
We collect images of oracle bone inscriptions and pair them with their corresponding modern Chinese characters. By mining the underlying pictographic semantics, we enable fine-grained analysis of oracle bone symbols. The resulting dataset covers 2,900+ oracle bone symbols and includes over 10,000 reasoning trajectories.
Future Outlook
We will further optimize the vision-language model (VLM) for oracle bone inscription systems by introducing spatial understanding mechanisms and reinforcement learning, to enhance the model’s ability to analyze the morphology, layout, and contextual relationships of oracle bone symbols. At the same time, we will construct a collaborative learning framework that integrates general-purpose reasoning with complex symbolic system reasoning, enabling bidirectional enhancement between domain-specific understanding and general intelligence, thereby comprehensively improving the model’s performance in ancient character recognition and multimodal reasoning tasks.
References
2025
-
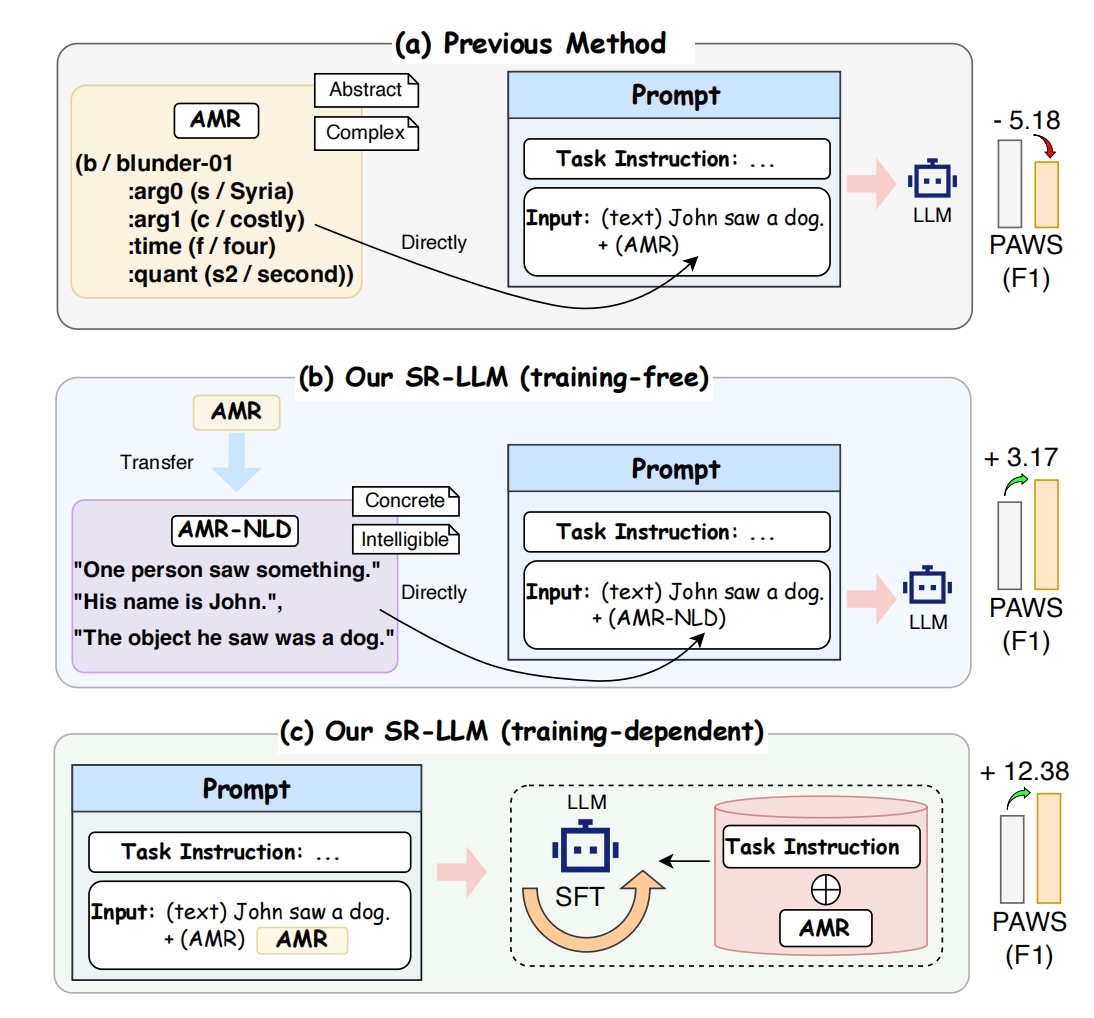 SR-LLM: Rethinking the Structured Representation in Large Language ModelIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
SR-LLM: Rethinking the Structured Representation in Large Language ModelIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025 -
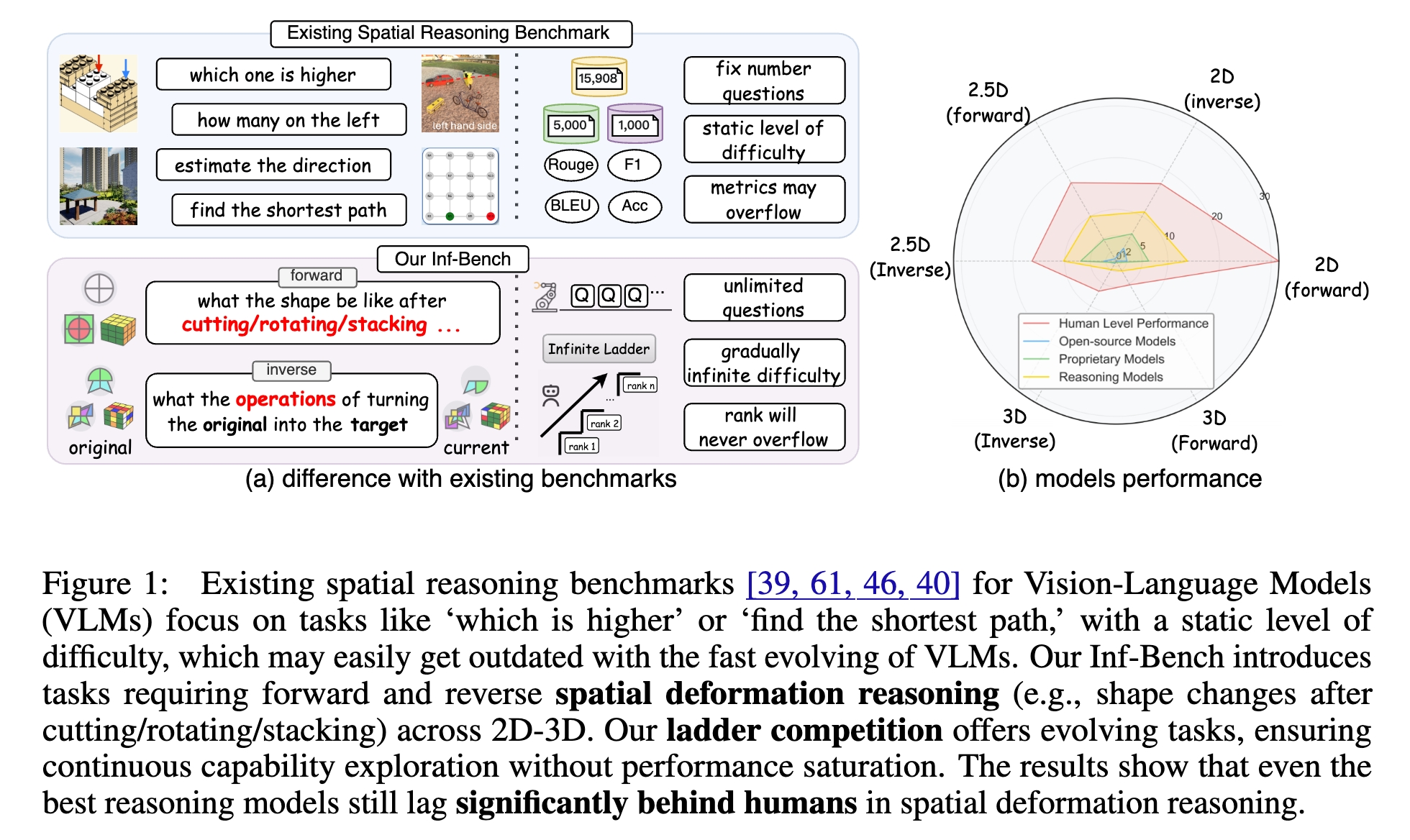 Ascending the Infinite Ladder: Benchmarking Spatial Deformation Reasoning in Vision-Language ModelsarXiv preprint arXiv:2507.02978, 2025
Ascending the Infinite Ladder: Benchmarking Spatial Deformation Reasoning in Vision-Language ModelsarXiv preprint arXiv:2507.02978, 2025

